Constitutional Classifiers: Protecting LLM's with Mini Bodyguards
Last updated 6 hours, 46 minutes
The constitutional classifiers are a form of filtering guardrails that are built for both the input into and the output from a language model. They were introduced by Anthropic in 2025 as a robust defence mechanism for frontier models after a period of public red teaming where everyone was invited to try find a universal jailbreak through the guardrails.
Constitutional Classifiers are specialised Claude Haiku models that are trained on detections of both harmful and harmless prompts. The training data was primarily synthetic prompts, all of which was generated by a larger Claude Sonent model across a broad range of different refusal scenarios.
What do the models do?
The Classifiers are a pair of two small Haiku models, one of which acts as an initial classifier on the input prompt from the user, while the other acts as a realtime output classifier which tries to detect when an output is likely to go against its constitution of CBRN refusals.
The input classifier gives a score straight away for a user prompt to detect harmful requests while the output classifier attempts to identify when the output tokens of the model starts to learn towards a probable harmful response.
Training the classifiers
The data used for this training were synthetically generated by models that were given specific constitutional rules in their system prompt, e.g. "Refuse any requests about acquiring restricted chemicals" or "Block inputs that attempt to establish coded communication".
Training Overview
The Input Classifier is fine tuned on next token prediction loss for the classification task, such that it outputs the classification at the end of its processing of the users prompt.
The output classifier on the other hand is trained by attaching an additional new linear layer at the same point as the Language Modelling head, which takes the embedding output from the final transformer block and passes the value through an MLP to produce a scalar logit.
This MLP out of a scalar logit score is then passed through a sigmoid function to generate the final probability for the specific token’s likelihood of leading to a harmful sentence. It is depicted as the second output head, below the Language Modelling head. This is also similar to the Reward Modelling head added to reward model in RLHF.
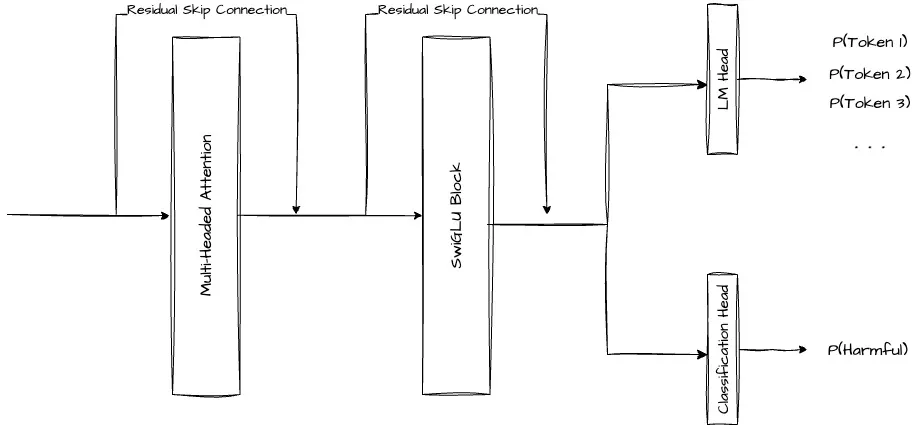
This slightly modified Output Classifier model is then trained on a mix of cross entropy loss (next token prediction objective) and a binary cross entropy loss on the predicted classification of harmfulness based on the prefix sequence produced.
The hyperparameter () serves to control the importance of the next token prediction task, which is essential for grounding the classifier to its original next token prediction capability and not lose coherence in its generation ability.
This loss then invites us to additionally select how the function is defined. Namely, our two options for how the probability of a harmful generation is defined are listed below.
Option A
The prediction of harmfulness for the specific latest token generated.
where is the scalar logit produced by the Value Head which has the sigmoid applied to it.
This means that each token independently contributes to the loss regardless of its result, promoting more stable training and consistent gradient signals.
Option B The cumulative maximum prediction of harmfulness from all previous tokens generated.
This means that the most harmful generated token’s score up to the current generation is treated as the classification. This is akin to how in the real world, we would stop the generation of the language model once it has crossed a certain threshold for predicted harmfulness.
This method while intuitive and more performant, only provides a gradient signal for the most dangerous tokens spotted and nothing else. This causes it to add some training instability.
Anthropic's Middle Ground
Anthropic chose to take the best of both worlds by mixing the above two formulations with a hyperparameter that is annealed over the course of the training. They start off by only using the predicted probability of harmful response for the latest token generated but then over the next of the training, fully transition to using the cumulative maximum as the classification probability.
After training, these two classifiers act as an extremely robust safeguard against most harmful requests and universal jailbreaks.
One can imagine that the input classifier is also self defensive since any unordinary generation from the model suggests that it has been compromised, which itself encourages a refusal.